Supermicro 和 NVIDIA 的 AI 工厂是完整的交钥匙解决方案,可简化企业级 AI 的大规模部署,以加快上线和创收速度,并提供包含计算、软件、网络和存储在内的全栈解决方案。Supermicro 提供针对性能和效率优化的 AI 基础设施,其完全集成的解决方案基于 NVIDIA 企业参考架构和 NVIDIA-Certified Systems™,确保全栈性能和兼容性。Supermicro 业界领先的机架级测试、验证和部署服务可确保高质量和无缝的即插即用部署,为 AI 部署提供全面保障。
Supermicro

首款上市的 NVIDIA 认证系统

机架级集成、测试和发货前验证

集群规模部署、服务和支持

存储与网络集成
英伟达

英伟达™(NVIDIA®)加速计算

英伟达™ Spectrum™-X 以太网网络平台

英伟达软件栈

英伟达人工智能数据平台
全栈解决方案
AI 企业
Omniverse
Run:ai


业界领先的最新人工智能技术上线时间。
- NVIDIA®(英伟达™)加速新技术率先上市的良好记录
- 灵活的积木式方法可加快采用周期
- 美国的月生产能力超过 5,000 个货架
- Supermicro Data Center Building Block Solutions® (DCBBS) 提供所需的一切,以促进 AI 工厂的部署

为您的企业量身定制灵活的端到端人工智能解决方案。
- 业界领先的广泛加速人工智能系统组合
- 灵活的模块化架构经过微调,可最大限度地提高企业环境的性能和效率
- 集群级集成专业知识,包括联网、测试和验证
- 适用于人工智能数据管道所有阶段的存储解决方案

久经考验的质量。无与伦比的性能。完全的人工智能信心。
- Supermicro 和 NVIDIA 之间的紧密合作确保性能优化的 AI 硬件可轻松集成到全栈 AI 解决方案中
- NVIDIA®(英伟达™)认证系统的全套产品组合可确保性能
- 单一供应商解决方案,对整个供应链进行全面的质量、完整性和兼容性控制
- 超越行业标准的完整 L11 测试和验证,实现即插即用的无缝部署
Supermicro NVIDIA-Certified Systems™ – AI 工厂的基础
Supermicro 灵活的模块化架构意味着配置和外形尺寸经过精心调整,可在企业环境中实现最佳性能和效率,从而简化了将 AI 优化硬件集成到现有企业环境中的过程,在这些环境中,散热、功耗和空间限制可能会限制一体式或现成解决方案的使用。Supermicro 业界领先的 NVIDIA-Certified Systems 产品组合已针对性能、可靠性以及与 NVIDIA 企业软件和 NVIDIA Spectrum-X 网络的兼容性进行了全面测试和验证,并构成无缝扩展 AI 工厂的 Building Blocks。

英伟达™(NVIDIA®)RTXPRO™服务器
提供各种外形尺寸和密度,以优化企业环境。从专为取代基于 CPU 的服务器而设计的行业标准 2U 系统,到专为实现最高性能而设计的热优化高密度系统。
- 2U、4U 和 5U 外形尺寸
- 每个系统最多可配备 8 个英伟达™(NVIDIA®)RTX PRO 6000 Blackwell 服务器版 GPU
- 支持多种工作负载,包括人工智能、高性能计算和视觉计算
- 针对空气冷却环境进行了优化,支持高达 35°C 的环境温度
- AMD EPYC™ 或 Intel® Xeon® CPU 选项
SYS-522GA-NRT

散热优化的 5U 系统最多可支持 8 个 GPU 和 IntelXeon 6 CPU
AS -5126GS-TNRT2

散热优化的 5U 系统最多可支持 8 个 GPU 和AMD EPYC 9005 系列 CPU
AS -5126GS-TNRT

散热优化的 5U 系统最多可支持 8 个 GPU 和AMD EPYC 9005 系列 CPU
SYS-422GL-NR

4U RTX PRO 服务器支持多达 8 个 GPU 和 IntelXeon 6 个 GPU
SYS-521GE-TNRT

5U RTX PRO 服务器支持多达 8 个 GPU 和第 5 代 IntelXeon GPU

英伟达HGX™系统
专为实现最高人工智能性能而设计的专用架构。英伟达™(NVIDIA®)HGX 系统采用下一代风冷架构和多种 CPU 选项,可提供前所未有的计算性能、密度和效率。
- 8U 和 10U 外形尺寸可在空气冷却环境中实现最佳系统性能
- NVIDIA B300、B200 和 H200 8-GPU 平台,配备 NVIDIA NVLink®,实现极致的 GPU 间通信
- AMD EPYC 9005 或 IntelXeon 6 CPU 选项
SYS-822GS-NB3RT

配备 NVIDIA HGX B300 8-GPU 和 IntelXeon 处理器的风冷 8U 系统
SYS-A22GA-NBRT

配备 NVIDIA HGX B200 8-GPU 和 IntelXeon 6 CPU 的 10U 风冷系统
SYS-821GE-TNHR

配备 NVIDIA HGX H200 8-GPU 和第 5 代 IntelXeon CPU 的风冷式 8U 系统
AS -8125GS-TNHR

配备 NVIDIA HGX H200 8-GPU 和AMD EPYC 9004 CPU 的风冷式 8U 系统

存储平台
完整的解决方案需要集成便于企业部署的存储硬件。与领先的数据管理 ISV 合作,Supermicro 能够支持 NVIDIA AI 数据平台,并在数据管理环境中实现 AI 工作流。
- 有多种外形尺寸和存储密度可供选择
- 存储硬盘选项,包括 EDSFF E3.S、U.2 和旋转介质
AS -1115HS-TNR

1U 12 盘存储系统

Supermicro 的 AI Factory SuperClusters 基于 NVIDIA 企业参考架构,为企业客户提供完整的机架级和集群级解决方案,确保全栈性能和兼容性,从而简化完整 AI 工厂的部署。Supermicro 的测试和验证超越行业标准,在发货前对所有节点进行全面测试,并进行集群级 (L12) 测试,以确保任何规模的客户都能实现无缝即插即用部署。Supermicro AI Factory 解决方案获得 NVIDIA 认可,涵盖基础设施配置、Spectrum-X 网络和软件参考堆栈,并基于 NVIDIA 针对 RTX PRO 6000 Blackwell Server Edition 和 HGX B200 的企业参考架构。
- 完整的机架级集成和验证
- 由 Supermicro 专家团队打造,交付后即可立即投入使用
- 英伟达™ Spectrum-X 网络技术
- 高速 AI 计算结构经过 NVIDIA 硬件和软件全栈的调整和验证,为 AI 工厂提供了无与伦比的以太网解决方案。
- 英伟达软件栈
- 运行 NVIDIA AI Enterprise、NVIDIA Omniverse 和 NVIDIA Run:AI 可确保兼容性
- 英伟达™(NVIDIA®)图形处理器
- 可选择英伟达™(NVIDIA®)RTX PRO 6000 Blackwell 服务器版 GPU 和 HGX B200 处理各种企业人工智能工作负载
- 存储
- Supermicro 与领先的独立软件供应商 (ISV) 合作,开发存储解决方案,以支持 NVIDIA AI 数据平台,并可无缝连接到 AI 工厂
- 热优化
- 由 Supermicro 专家团队打造,交付后即可立即投入使用
- Supermicro NVIDIA 认证系统
- 经过测试和验证,确保兼容性和性能
| GPU | 英伟达™(NVIDIA®)RTX PRO 6000 Blackwell 服务器版图形处理器 | NVIDIA HGX B200 | NVIDIA HGX B300 |
|---|---|---|---|
| 最大群集大小 | 每个可扩展单元多达 32 个节点、256 个 GPU | 每个可扩展单元多达 32 个节点、256 个 GPU | 最多支持 32 个节点,256 个 GPU |
| 每个机架的节点数(典型值) | 每架 4-8 个 | 每架 4 个 | 每架 4 个 |
| GPU 系统节点 SKU |
|
|
|
| 每个节点的 GPU 配置 | 8块 NVIDIA RTX PRO 6000 Blackwell 服务器版(每块 GPU 配备 96GB GDDR7 显存) | 8块 NVIDIA HGX B200(每块GPU配备192GB HBM3e) | 8块 NVIDIA HGX B300(每块GPU配备288GB HBM3e) |
| 机架功率(4 节点) | 33.3-36.6 千瓦 | 53.6 千瓦 | 60千瓦 |
| 网络 | 英伟达™ Spectrum-X | 英伟达™ Spectrum-X | 英伟达™ Spectrum-X |
| 英伟达软件栈 | NVIDIA AI Enterprise/ | NVIDIA AI Enterprise/ | NVIDIA AI Enterprise/ |
| 目标部署用例 | 人工智能推理/检索增强生成(RAG)、高性能计算和视觉计算 | 基础AI模型训练、大规模AI推理以及FP64高性能计算工作负载 | 基础人工智能模型训练、大规模人工智能推理和高性能计算工作负载 |
| 链接 |

英伟达™(NVIDIA®)人工智能软件平台
Supermicro 的 NVIDIA 认证系统™ 已针对性能、可靠性和与 NVIDIA AI 软件堆栈(包括 NVIDIA AI Enterprise、NVIDIA Omniverse 和 NVIDIA Run:ai)的兼容性进行全面测试和验证,从而能够在任何地方(无论是云端、数据中心还是边缘)构建和部署生产就绪的智能体 AI 和物理 AI 系统。
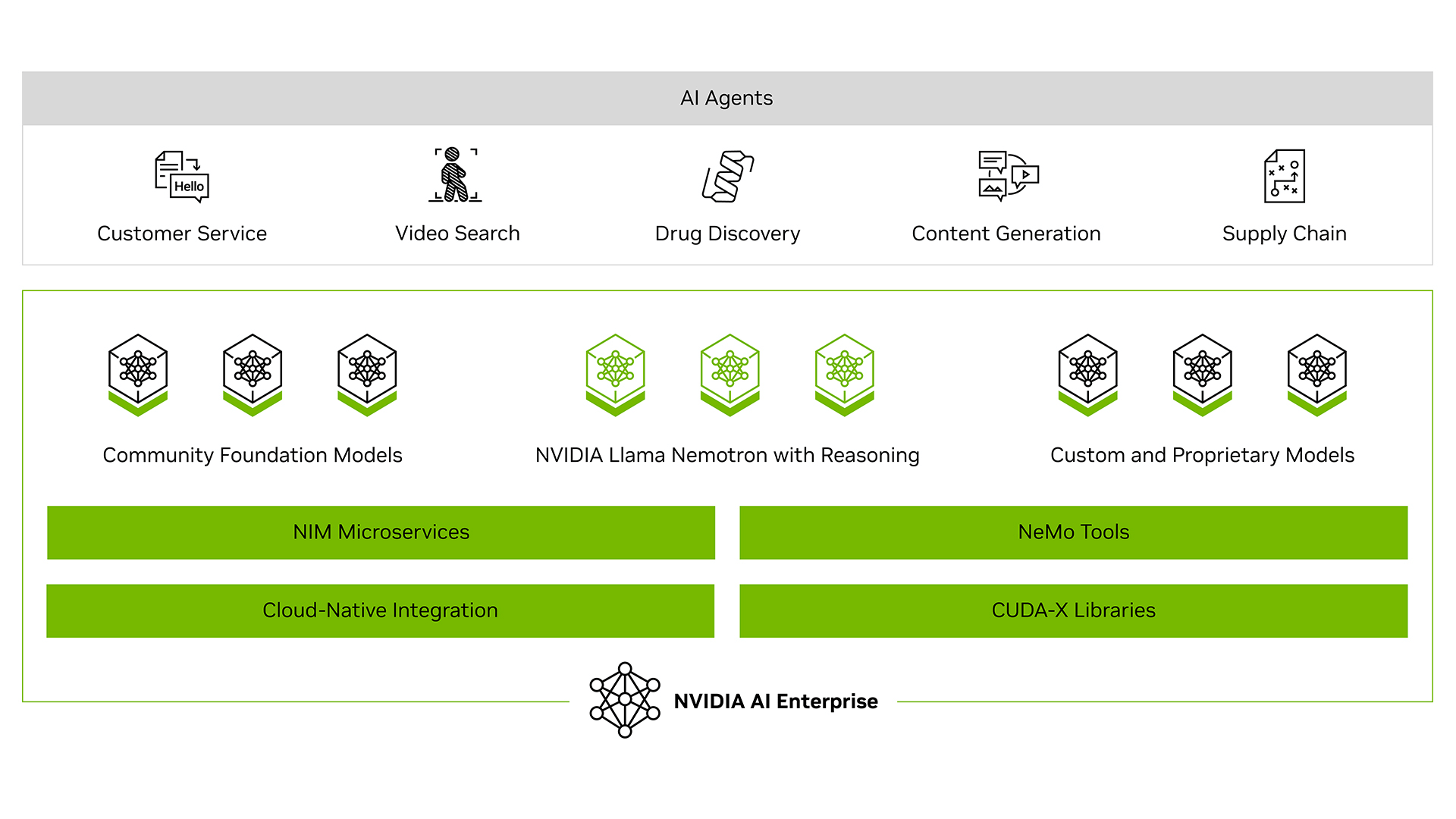


NVIDIA Omniverse
NVIDIA Omniverse 是一个包含 API、SDK 和服务的平台,使开发人员能够将 OpenUSD、NVIDIA RTX™ 渲染技术和生成式物理人工智能集成到工业和机器人用例的现有软件工具和仿真工作流程中。

英伟达™ Run:ai
NVIDIA Run:ai通过对整个人工智能生命周期进行动态协调来加速人工智能操作,最大限度地提高GPU效率,扩展工作负载,并以零人工操作的方式无缝集成到混合人工智能基础架构中。
完整的AI数据生态系统,旨在Supermicro系统上加速。
Supermicro存储服务器为NVIDIA AI数据平台提供高性能硬件基础,并经过行业领先的存储软件合作伙伴验证。无论您运行DDN、VAST Data、Weka、IBM Storage Scale、Cloudian、Everpure还是Nutanix,Supermicro都能提供计算、网络和存储基础设施,以实现企业数据中RAG、语义搜索和AI代理的智能知识检索。
在任何规模下加速人工智能发展
IBM Storage Scale在Supermicro系统上提供经过验证的企业级并行文件系统,并与AI工作负载深度集成,从而在分布式环境中实现快速、安全的数据访问。
AI 数据的全闪存性能
Everpure AI数据平台集成了Everpure平台和FlashBlade与Supermicro PCIe GPU服务器,以加速企业AI数据工作负载。

充分释放企业数据的全部价值
Supermicro存储基础设施支持NVIDIA AI数据平台,将您现有数据转化为AI就绪的知识库,用于RAG、语义搜索和智能AI代理。您的数据保持安全并驻留在本地,同时几乎实时地供AI应用程序即时访问。

专为 AI 工厂打造
AI数据平台与Supermicro AI工厂计算基础设施协同工作,将智能数据访问与高性能模型训练和推理相结合。

智能知识检索
持续采集、嵌入和索引非结构化企业数据——包括文档、图像、视频等——以便人工智能应用程序能够即时检索到所需信息。

安全无妥协
数据绝不会被移动或复制。向量嵌入是在原地生成的,从而保留了现有的访问控制和数据主权要求。

始终与时俱进,始终切合实际
持续的数据处理确保人工智能的输出基于您最新的信息,从而减少“幻觉”并提升决策质量。
服务和现场部署
通过从规划到持续支持的全面专业服务,加速您的数据中心部署。Supermicro 全球服务提供端到端专业知识,包括数据中心设计、解决方案验证和专业的现场部署——无论您是从零开始建设、改造空冷系统为液冷系统,还是在托管设施中进行部署。我们的集成方法可缩短上线时间,并确保更高质量的安装,同时提供持续的现场支持和针对关键任务正常运行时间的 4 小时响应选项。


