Supermicro Data Engineering Solutions
Enabling Artificial Intelligence and Generating Insights from Data
Supermicro Solutions to Engineer Artificial Intelligence with Data
Addressing the Data Challenge for AI
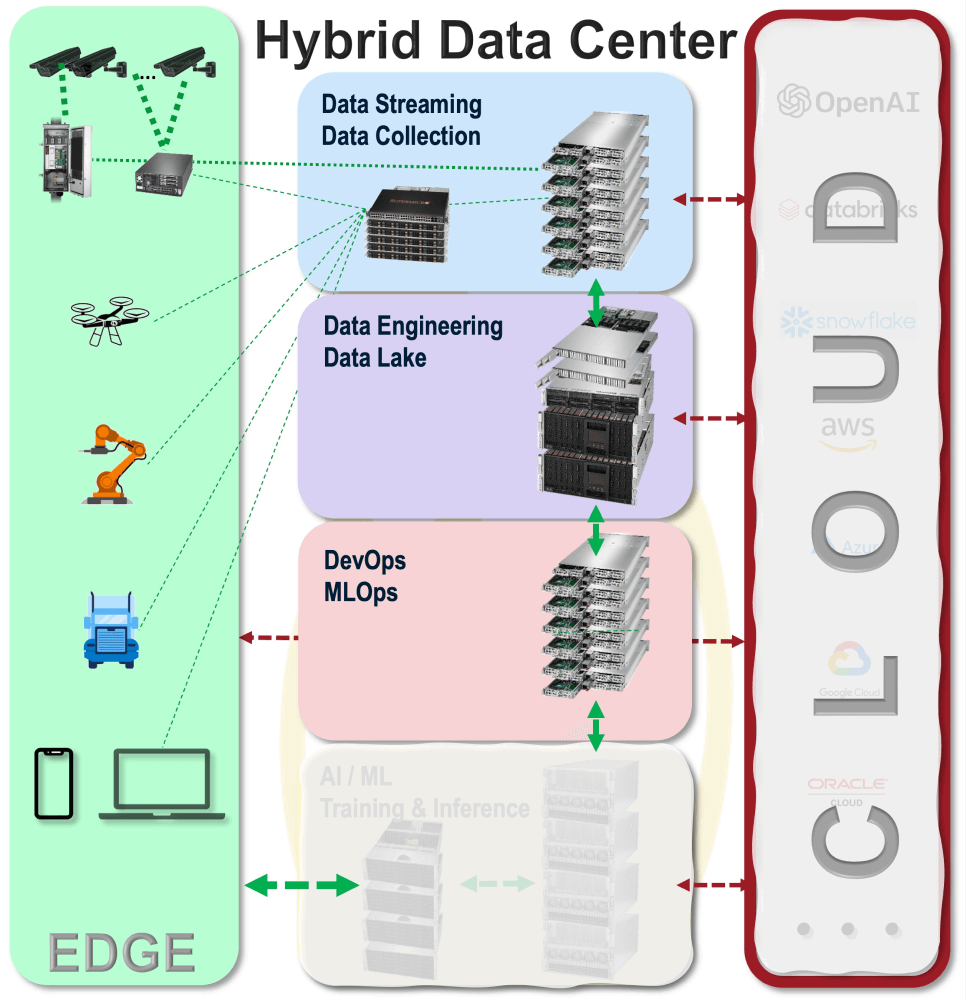
AI Training and Inference on new data are key to create new services to customers and to optimize business operations. With low-cost sensors and increasing social interactions with customers over the internet, businesses can take significant advantage from the increasing daily volume of data to improve AI systems. Implementation data flow systems that respect customer data privacy, the following key functions support AI training and inference:
- Data streaming to manage data collection from edge devices and the internet
- Data stream to systems running Apache Kafka, NiFi, and Flink
- Data engineering on data extracted from data lake, setting up data pipelines for AI workflows
- Data pipelines to direct data into different AI workflows
- Data extraction and transformation using Apache Spark
- Data warehousing using Apache Hadoop File System (HDFS), Impala, Hive Iceberg, and others
- DevOps and MLOps to drive workflow in AI training and inference systems
- Kubernetes to manage containers
- Apache Spark graph processing
These components are available from the opensource community.
Supermicro partners with Cloudera, open source, and other software partners to provide these solutions to enterprise customers. Cloudera integrates the software components to run on Supermicro systems and provides enterprise level software support to developers and customers. Cloudera has organized the software components into manageable platforms and modules for deployment, as well as adding data provenance and data security features.
Cloudera integrates a vast set of open-source software, organizes them into a platform that runs on-premise as well as in the cloud, and provides enterprise level support to help customers build data collection, data analytics, ETL, and data lake house systems that are scalable and reliable. In additional, Cloudera has added data provenance to ensure data trust worthiness
Opensource software such as Apache® Spark™, Kafka, Flink, Nifi, Iceberg, Hadoop, and many more advances bring about the latest software systems and architectures that collect data, analyze data, engineer data, and store data. These technologies simplify and expedite artificial intelligence by providing frameworks to organize and manage data to deal with changes over time. Open-source software provides the latest technologies, while users need to maintain and support their software infrastructure, unless they use software organized by companies like Cloudera.

Supermicro And Cloudera Deliver Reliable Data Collection For AI & Analytics
Supermicro GrandTwin™ Servers Running Cloudera Flow Management and Stream Processing

Supermicro And Cloudera Deliver Reliable Data Collection For AI & Analytics
Supermicro CloudDC Servers Excel at Running Cloudera Flow Management and Stream Processing

Supermicro, Cloudera, & NVIDIA Accelerate Enterprise Data Analytics
How Supermicro Ultra Servers and Cloudera Data Platform Extract Deep Insights from Massive Amounts of Data

Supermicro A+ Server AS -1124US-TNRP Extends OLTP Performance Leadership with TPC Benchmark® C (TPC-C®)
Supermicro AS -1124US-TNRP Powered by AMD EPYC™ 7003 Series Processors Excel at Database Performance

Supermicro ATEMPO Data Migration Solution for Unstructured Data
Miria, a data migration software platform for Petascale Unstructured File Sets Excels on Supermicro servers

Supermicro 2U 4節點TwinPro²參考架構EsgynDB®
Supermicro和 Esgyn 聯手推出了一個大數據設備,使用EsgynDB提供更快的業務洞察力,一個大數據融合數據庫優化運行在Supermicro 2U 4節點TwinPro2 SuperServer平台上。

World record Performance on Data Analytics Workloads
With Supermicro AS -1114S-WN10RT Powered by AMD EPYC™ 7003 Series Processors